
When you think of learning, do you picture mean teachers, old books, and dirty school toilets? Wrong, these are things that hinder your learning. According to the Cambridge Dictionary, learning is “the acquisition of knowledge or skills through study, experience, or instruction.”1
If someone had asked you in eighth grade what you fundamentally thought about learning, the answer would certainly not have been that learning is such a great thing that you read specialized articles on the topic of deep learning in your free time. So you’re rightly asking yourself why I’m telling you about it now. After all, you’re no longer in school. Let me give you three good reasons why the topic of learning is still relevant to you.
Reason 1: Knowledge is not constant. It is changeable. Some even say that knowledge has a half-life. Knowledge develops, gets marginalized, or changes. Earlier knowledge can be subsumed into new knowledge. It may be that knowledge is no longer needed or is only temporarily not needed. Who has ever wondered why children still learn to read maps in school, even though everyone has access to Google Maps? Here, survival-critical knowledge is passed on across generations, which might be needed if all servers crash. Compared to school knowledge with a half-life of 20 years or knowledge from physics with five to ten years, the half-life in the technology sector is very short, with two to three years, and in IT, it is less than two years. This makes IT an industry with high learning needs.
Reason 2: Machines are learning now, and you work with machines. Maybe you’ve heard of artificial agents – of course, you have. One of the smartest artificial students might be ChatGPT. He, of course, attends a private school run by Open AI’s “Human AI Trainers” and is trained through “supervised fine-tuning.”2
Reason 3: Nature has always been a model for terrible, amazing, or life-changing innovations in the past. Perhaps you’ve noticed that airplanes have wings like birds to maintain balance while flying.3 You know that the Velcro fastener on children’s shoes is inspired by burdocks4, and you’ve heard of Atomic Design5, which uses basic concepts from chemistry. When it comes to machine learning, humans – each one of us – are the perfect model.
So learning is not just a topic for educators, but “a lifelong process to keep up with changes.” Learning is a prerequisite for efficiently completing a task and keeping work life exciting. It is a complex process and a central subject of investigation in various disciplines – including computer science, mathematics, neuroscience, psychology, and even philosophy. The topic is so comprehensive that we have to limit ourselves to one core aspect in this article: The relevance of data quality in the learning process.
First, some terminology:
- Data are fragments of symbols and characters. When viewed in isolation, the context may be missing.
- Information gives data context and is thus processed data.
- Knowledge brings depth and understanding to this information and makes it usable.
How do Data enter the System?
Through our senses. Just in case elementary school knowledge has faded: our senses are touch, sight, hearing, smell, and taste. When attentively reading a blog post from adesso, the eyes are mainly involved, while listening to the adesso Podcast IT-Tacheles mainly involves the ears. According to Bernd Weidemann’s Naive Sum Theory from 2002, it is particularly useful when learning to address multiple senses, or input modalities, which makes “doing” the most effective. According to Richard E. Mayer’s Cognitive Theory of Multimedia Learning (CTML), different modalities of presenting information are processed in the auditory-verbal or visual-pictorial channels. Whether one reads a text in a professional journal or hears it in a podcast, it is ultimately processed in the same auditory-verbal channel. It is not useful to play the same channel multiple times simultaneously. Supplementing text with images is sensible as it directly addresses two channels – auditory-verbal and visual-pictorial. Therefore, a code-along video with spoken explanations is a good thing. While it is almost impossible to listen to a podcast while writing a proposal. All just theory. Knowledge is not constant.
Processed data are stored in various forms from the outside world. In the following, we call this “form” representative encoding. This can be visual in images and texts, auditory in speech or music, and also tactile through touch, such as in the Interaction Room of the Dortmund office.
Artificial agents don’t have senses, do they? Yes, they do. We differentiate between pure software agents and hardware agents, with hardware agents having sensors – cameras, pulse monitors – to perceive information from their environment, and also actuators – like speakers or wheels – to explore what happens when they vacuum socks.
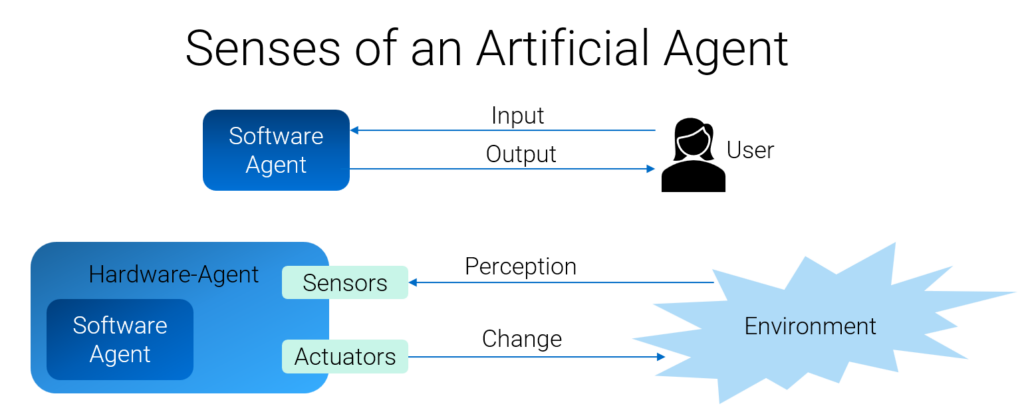
What does all this have to do with data quality? How qualitatively processed data are perceived depends not only on their internal nature. The properties of the interfaces between a system that holds information, like a vocabulary book holding words in a table or search engines holding clickstream data in digital roadmaps, and the respective input modality – ears or command line – should be considered when processing the data. Depending on the type of information to be represented, a system can present the data in such a way that they can be read quickly, completely, and without misunderstanding by the readers at the interface with as little computing power as possible. Various representation encodings are suitable for this to different extents.
Which Representative Encoding suits me?
Whether it is a new test framework or an entirely new subject area: we all repeatedly face new knowledge gaps that need to be filled through active and, ideally, efficient learning. Look at the word cloud and consider which presentation forms you most often use to acquire new knowledge. Do you think there are different types of learners? Some learn better with texts, others better with images?

Of course, each of us has our “go-to” sources, and there are certainly people who only turn to a book in an emergency. But in reality, there are no different types of learners. The most suitable representation of information does not depend on the learner’s preference but on the type of information to be conveyed.
The best Representative Encoding
Possible representation forms are linguistic, like natural language in the form of books and audiobooks, or formal, like Java or sheet music. Others are visual, like icons, smileys, or maps. Imagine, instead of an emergency exit sign, you receive a textual description of the route to the nearest emergency exit upon entering a building, depending on where you are. How safe do you feel then?
Another example: if you ask at the tourist information in London where the British Museum is, it will probably be shown to you on a map. If you ask when the next bus to it leaves, you expect a spoken time or a written bus schedule. And if you ask how to recognize your bus, you probably expect a picture of a red bus. Map, speech, writing, image – simply swap the representative encodings used for the respective information in the above example. A textual description of the bus’s appearance instead of an image will never be read as quickly. Additionally, I assume the reader already has a visual representation of the color red, the double-decker, and the vehicle in their system, similar to my internal representation.
What makes a good Representative Encoding?
The quality of a representative encoding depends on how easy it is to process and whether it delivers all information correctly and completely. Processing efficiency, accuracy, and completeness are very important, as every system has its limits. Our memory can process a maximum of four to nine pieces of information simultaneously. Cognitive resources also have their limits. According to the theory of cognitive load, these resources are now distributed across three processes:6
- Intrinsic cognitive load: It is not really changeable. The more complex the topic, the higher the resource requirement. The effort depends on how difficult the topic is. It is easier to learn the basic HTML tags than to understand the concept of Kubernetes clusters.
- Germane cognitive load: describes the actual cognitive load from relevant processes such as holding information in working memory, selection, self-explanation, etc. If this load is particularly high, the information is likely to be processed efficiently.
- Extraneous cognitive load: is the capacity needed to understand what the representative encoding represents. The more inappropriate and difficult it is to read, the more cognitive resources are needed. The goal is to keep this as low as possible.
In 2002, Valcke introduced a fourth cognitive load, the meta-cognitive load.7 This load arises when we, for example, control the learning process, evaluate our learning success, and, if necessary, adjust our learning strategy. The extent of this fourth load depends heavily on the learner’s prior knowledge.
In summary, we want to keep the extraneous load as low as possible to efficiently integrate new data and have more capacity for the actual processing process. The extraneous load depends on the quality of the processed data.
How can we reduce the Extraneous Load?
If a UX/UI expert is sitting in your office right now, they can probably tell you a lot about it. Feel free to ask. Richard E. Mayer mentions at least these three important principles in his book on multimedia learning to keep the extraneous load as low as possible in representative encoding:
- The coherence principle8: Leave out all interesting but irrelevant additional information. That the first idea of CSS came up in 1994 is interesting but helps no one learn CSS.
- The redundancy principle9: Do not present the same information more than once.
- The principle of spatial and temporal contiguity10: Information that belongs together should also be presented together. If you hide requirements that belong together in Confluence, you have not fulfilled this principle.
In the field of artificial intelligence, data quality is an important topic, which may not be so surprising now. Because just like with us humans, data is of high quality when it is “suitable for the intended use in operation, decision-making, and planning.”11 Typical quality defects of data and datasets, whether in the test data, backlog, or file explorer, are duplicate instances (redundancy principle), missing packages and gaps (completeness), missing connections (spatial and temporal continuity), and irrelevant data for the recycle bin (coherence principle). Insufficient data quality leads to confusion, lack of trust, poor decisions, and ultimately increased costs in almost all areas.
Meet your Colleagues with appropriate Data Quality
Like an artificial agent, we also need to read, select, organize, and interpret data. Only we are rarely celebrated when we do it well. Data quality can be a challenge. How well your colleagues handle data is not in your hands. But you can influence the quality of the processed data you provide. To achieve high data quality, many things need to be considered – from completeness to arrangement to appropriate presentation. Every workshop, training, and specialized article aimed at conveying knowledge involves a lot of work. The global market for e-learning platforms and online education is worth several billion euros for a reason. High-quality processed data comes at a price.12 Next time you write a story, program with a colleague, or present your latest concepts to clients, remember that you are working with people who want to acquire knowledge and skills from you. Clean code, clear and complete communication, and an appropriate presentation without frills reduce headaches, lift spirits, and help us learn together.
Sources
- Formal, non-formal, and informal learning: What are they, and how can we research them?, 2022, Martin Johnson & Dominika Majewska, Cambridge University Press & Assessment ↩︎
- https://openai.com/index/chatgpt/ ↩︎
- https://www.dlr.de/next/desktopdefault.aspx/tabid-6628/10887_read-24703/ ↩︎
- https://www.kindernetz.de/wissen/die-klette-100.html ↩︎
- https://atomicdesign.bradfrost.com/ ↩︎
- https://www.didaktik.physik.uni-muenchen.de/multimedia/lernen_mit_multimedia/psycho_theo/cognitive_load/index.html ↩︎
- Chen, Chun-Ying & Pedersen, Susan & Murphy, Karen. (2011). Learners’ perceived information overload in online learning via computer-mediated communication. Research in Learning Technology. 19. 10.3402/rlt.v19i2.10345. ↩︎
- https://www.cambridge.org/core/books/abs/multimedia-learning/coherence-principle/4E80B70CB76E2166B76E5653EBDE7D3E ↩︎
- https://www.cambridge.org/core/books/abs/cambridge-handbook-of-multimedia-learning/redundancy-principle-in-multimedia-learning/448A5532008EB4B4BA17DBEB5A421920 ↩︎
- https://www.cambridge.org/core/books/abs/multimedia-learning/spatial-contiguity-principle/B9B79EDC777C375C7ED410B82EF80247 ↩︎
- Fadahunsi KP, Akinlua JT, O’Connor S, Wark PA, Gallagher J, Carroll C, Majeed A, O’Donoghue J. Protocol for a systematic review and qualitative synthesis of information quality frameworks in eHealth. BMJ Open. 2019 Mar 5;9(3):e024722. doi: 10.1136/bmjopen-2018-024722. PMID: 30842114; PMCID: PMC6429947. ↩︎
- https://de.statista.com/statistik/daten/studie/1401742/umfrage/umsatz-markt-online-bildung-weltweit-segmente/ ↩︎